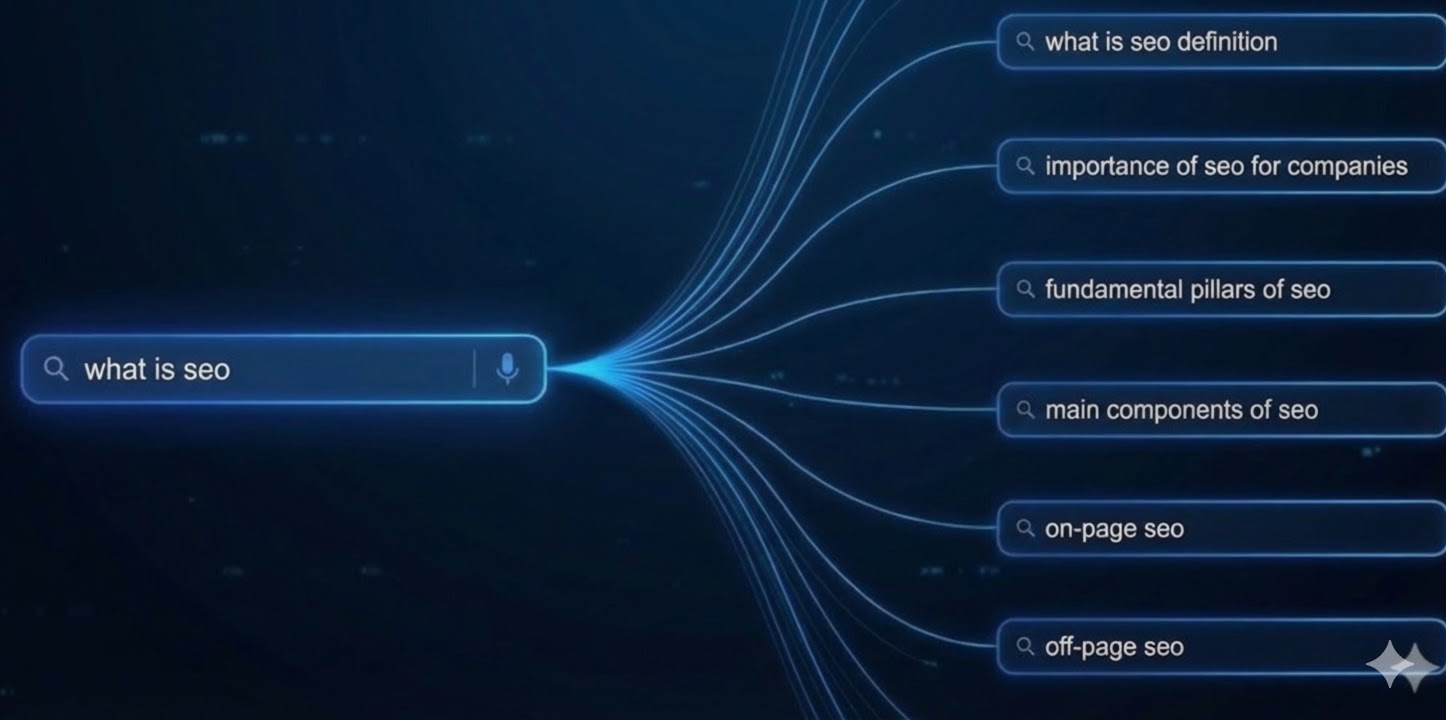
What is query fan-out and how is it used in AI SEO?
Query fan-out is a technique in which a user's main query is automatically broken down into multiple subqueries to cover broader context, various user intents, and to obtain more accurate information for the AI response.
If you ask "what is seo?" in Google AI Mode, a custom version of Gemini will run background searches such as: what is seo definition, seo importance for businesses, basic seo pillars, main seo components, on-page seo, off-page seo. It is as if you searched for several queries at once in traditional Google Search.
Based on these searches, the AI finds sources such as webpages, videos, information on Google Maps, etc., and compiles its answer from them.
For the user, this has two major advantages:
- It saves time. It would take a human much longer to search for all these queries, read the sources, and understand the topic.
- AI also searches for queries that a human wouldn't think of. An average user searching for "what is seo" doesn't know they should also search for "on-page seo" or "off-page seo". However, the AI already hase some background knowledge, enabling it to determine which advanced queries and information are required to formulate an answer.
Google talked about this technique at I/O 2025 in late May:
Query fan-out and grounding
Query fan-out is part of a broader process known as grounding. The large language model (LLM) powering the AI often makes things up and inherently cannot verify if what it generates is actually true. This is called AI hallucination.
Grounding is a process where AI is used "only" to summarize information from webpages or other sources, which significantly reduces the hallucinations in AI responses.
In practice, the AI system usually does not process the entire page. Instead, it looks for the passages most relevant to the question. These passages are called chunks. A chunk is usually one paragraph, a list, a section with a heading, or a piece of a table. The system divides the page into multiple parts, compares each with the query, and selects only the most relevant ones. From these, the model then compiles the answer.
In AI SEO, we optimize passages of pages (chunks) in addition to entire pages.
Grounding also helps solve the problem of information freshness. Every trained language model has a knowledge cut-off date, i.e. the date when data collection for its training ended. After this date, the language model knows nothing about the world, because information after this date was not used for its training. But if the AI uses search in the background (grounding), it can look up current information and correctly answer questions where being up-to-date is important.
That is why capable AI systems tend to rely on grounding for topics such as news, trends, and anything time-sensitive. But some important AIs, such as Google AI Overviews, use grounding all the time, even for questions that are not about current information.
How can you appear in AI answers?
There are two main ways to appear in AI answers: as a cited source or as an entity mentioned directly in the response.
As a cited source
If your page seems relevant for any of the subqueries searched during the query fan-out process, the AI pulls information from it and mentions it as the source of that information. The source doesn't have to be the whole page; it can be just a part of your page, or your YouTube video, an image, a Google Maps listing—there are many sources.
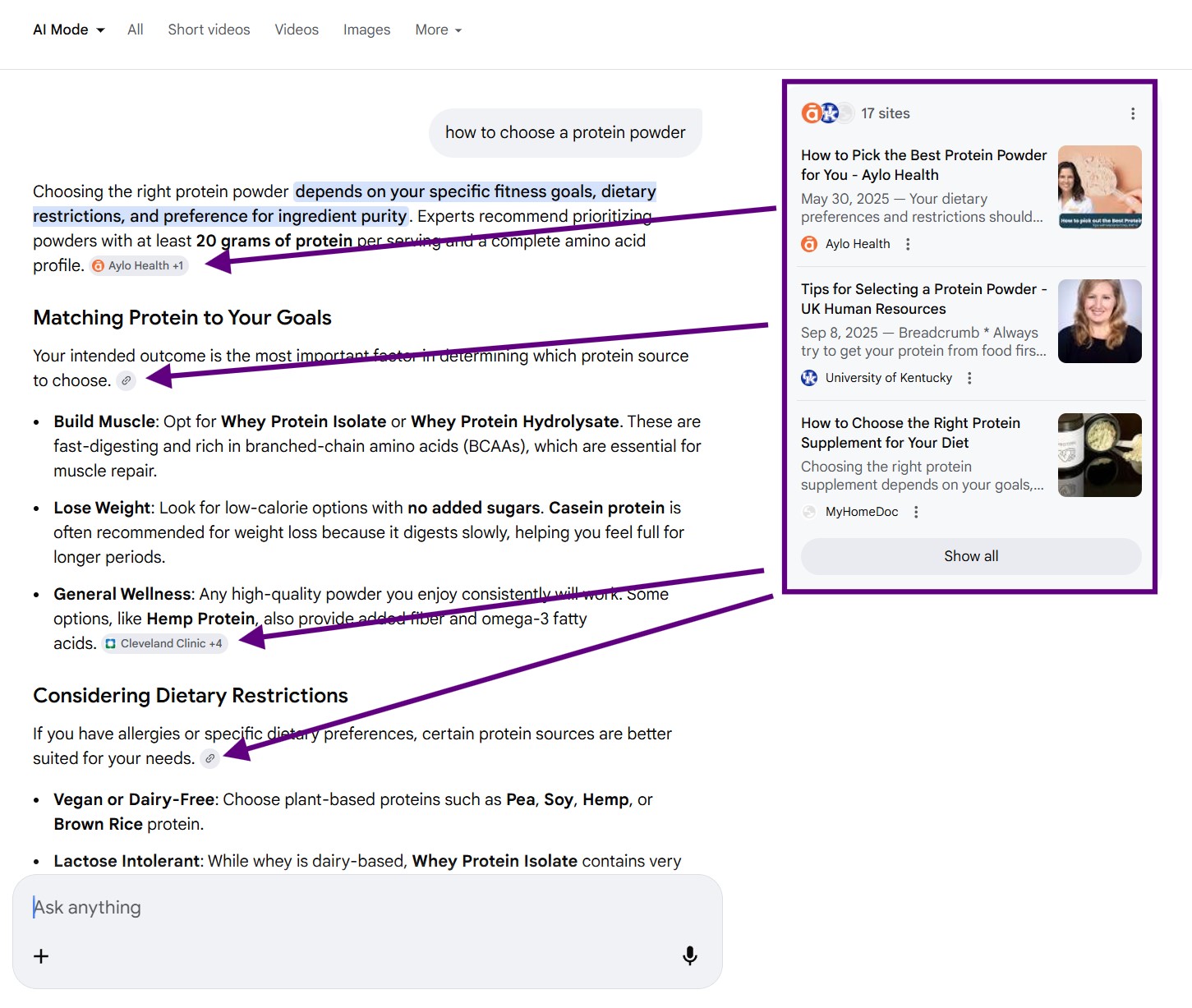
People click on sources much less than on traditional search results, after all, the AI gave them the main answer and they can ask for more details. But I would compare it to a better billboard. You want to be there for your topics because of brand visibility.
Mostly, we want to rank as a source for informational queries related to our business.
As an entity in the response
If a user enters a commercial query, e.g., "which air fryer should i buy", the main goal is for the AI to recommend our brand directly in its answer.
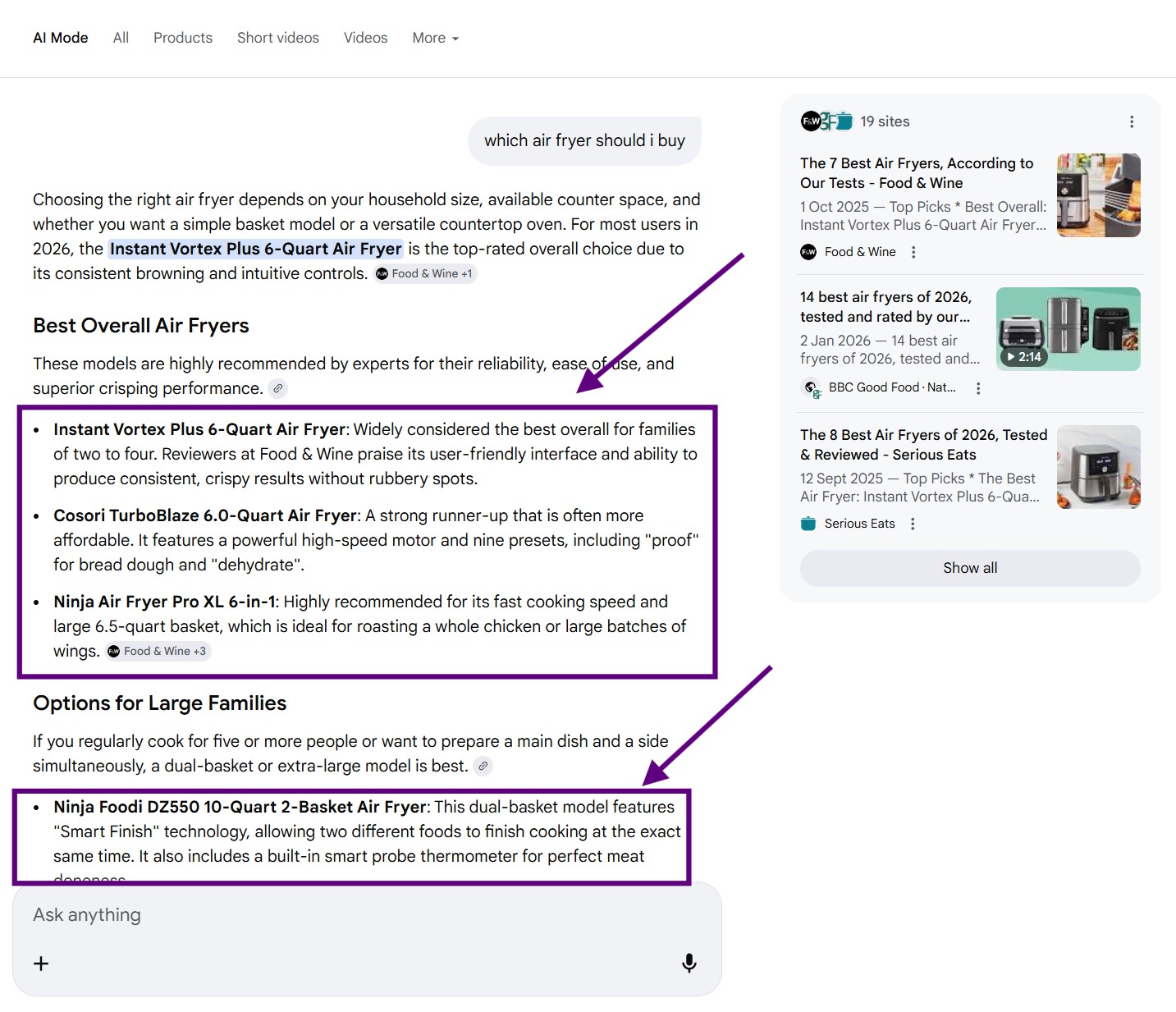
However, for it to recommend us, we must fulfill at least one of the following:
- Be directly in the LLM's training data, so the AI can mention or recommend our brand "from memory". This is not much related to the query fan-out process. Where does the AI get its training data is perhaps for another time.
- Be in the sources the AI cites from. This is directly related to query fan-out because the AI finds sources using subquery searches.
We target some subqueries with our content
We want to cover some subqueries with our own pages. For example, if you see that the AI searches for the query "key features of small business CRM software", we can target this query with a dedicated page, or we can target it with a part of a page (chunk).
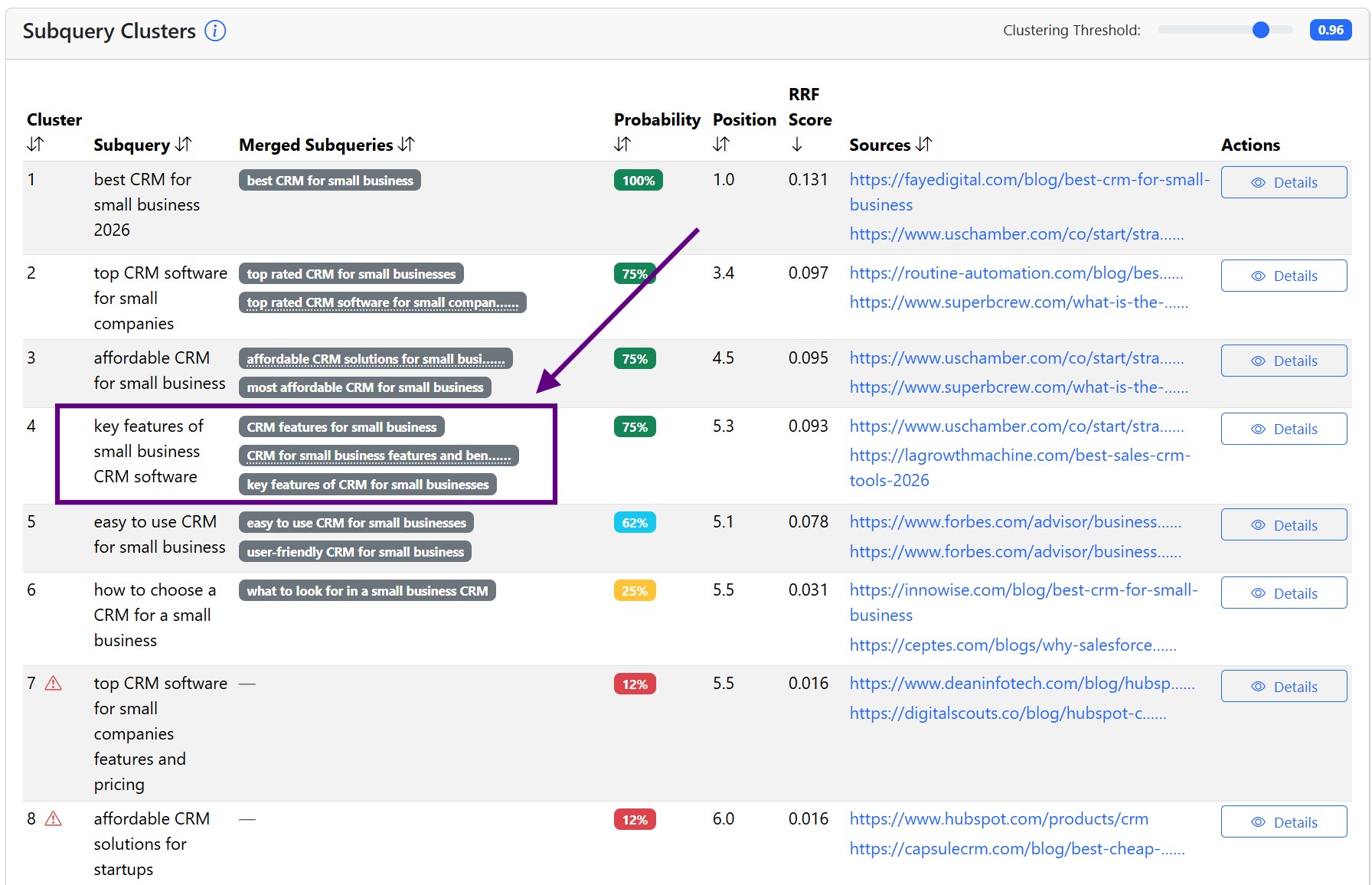
But it does not make sense to target every sub-query this way.
We target some subqueries through reputation management
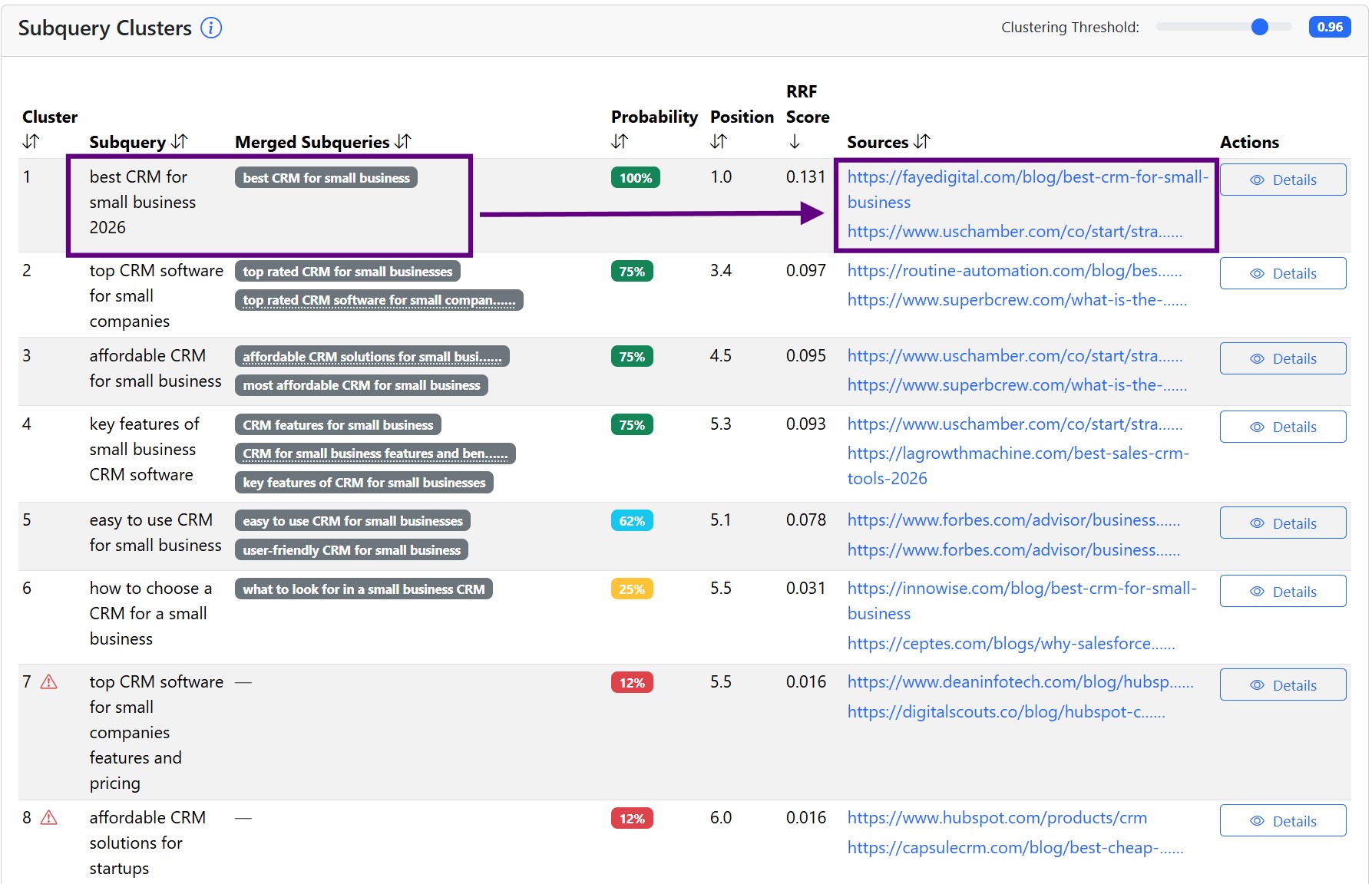
If the AI searches for the subquery "best CRM for small business 2026", it wants to find comparisons by third parties. Publishing your own Best CRM systems article and ranking yourself at the top is not the best approach. Many websites still do this, it's called self-promoting listicles. Google has increasingly treated this kind of self-promotional content as low-value or spammy.
With queries like "best CRM systems", we take a more effective approach. We reach out to pages that the AI uses as a source for this query and try to get our brand mentioned on those pages, preferably in a good context.
What is query fan-out analysis?
Through query fan-out analysis, we identify and prioritize opportunities in two areas:
- Creating new content or improving existing content that addresses a subquery, very similarly to how we did it with traditional keywords and traditional SEO.
- Finding external sources the AI relies on where our brand is either missing or mentioned in the wrong context.
In AI SEO, we need to know what queries the AI searches for when we ask it our key prompts.
(You get it, keywords - key prompts.)
If you've ever done keyword analysis, understanding query fan-out analysis is easy.
In keyword analysis, we map what people are searching for. In query fan-out analysis, we map what the AI is searching for.
The searched queries overlap to some extent, but the AI also searches for queries that people don't. Simply because it knows more about every topic than the average person and because it is very easy for the AI to add another search for a subquery.
In order to find out what queries the AI searches for, we need a tool.
Naive vs real query fan-out
Most query fan-out tools do something I call naive query fan-out. Basically, you don't even need these tools because you can simulate that approach yourself. You simply ask the AI something like this:
What subqueries would you search for in a query fan-out technique if a user asked you this query: "what is seo". Return only a list of 8 subqueries.
The output will look something like this:
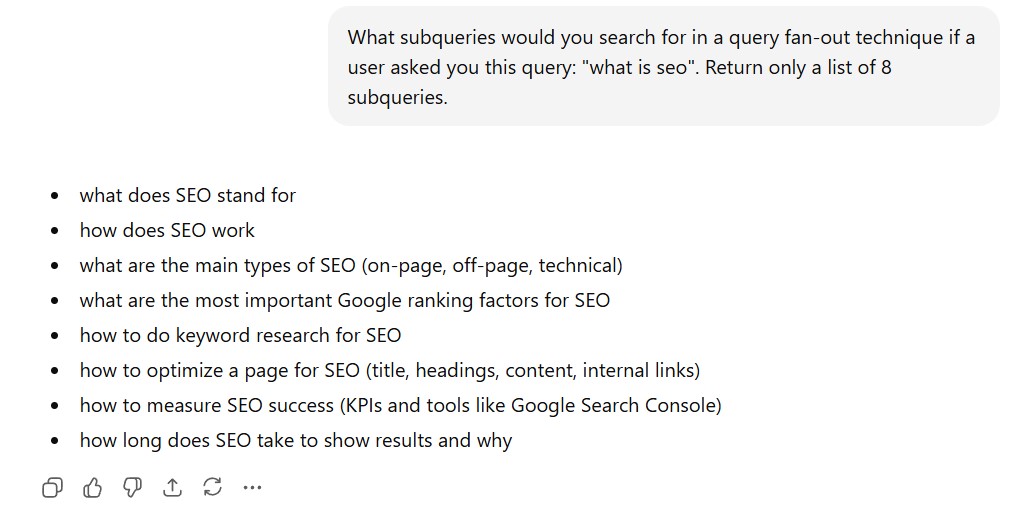
Not every prompt triggers a query fan-out
At first glance, that looks nice and well. But when you actually ask ChatGPT the above question, it won't do any query fan-out and will answer from memory instead. With naive query fan-out, you don't know whether the AI actually uses grounding for a given prompt or query.
You can partly work around this by asking first if the AI would even use grounding for the given query. But even if you tried it on a prompt where grounding will certainly be used, for example "summarize the latest seo news for me", you will see that the returned list does not match the queries the system actually runs.

We have a Google Chrome extension that reveals ChatGPT's actual search queries shows that in reality ChatGPT searched for these queries:

There is one important thing to notice...
Retrieved content influences the subsequent subqueries
The information ChatGPT found for the previous query can influence what the next subqueries the model searches. In other words, ChatGPT does not decide all of its searches in advance. First, it searches for something, finds information, and based on the found information, it searches for something else. So the content it retrieves affects which subqueries come next.

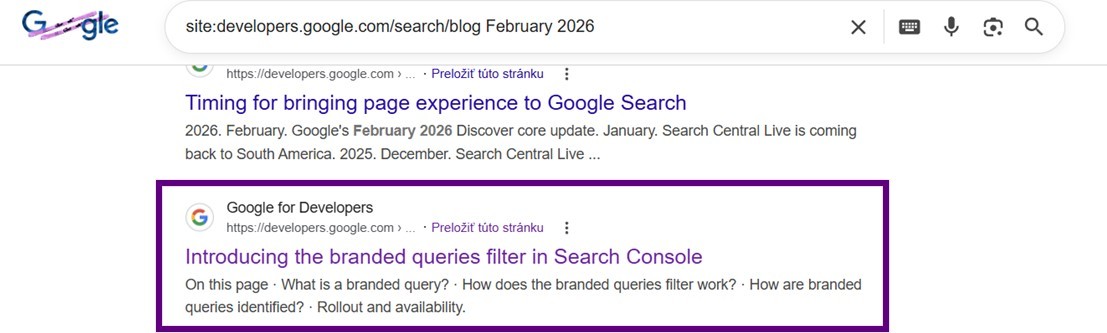
Notice the query "February 2026 Search Console update branded queries filter SEO". It could not have known in advance that it should search for a branded-queries filter in Google Search Console. It could not have known that this is currently being discussed. The GPT model doesn't have it in its training data. It found out only when it searched for this query "site:developers.google.com/search/blog February 2026".
See that even on Google it's one of the top topics for that search:
This means that without simulating the entire AI response process, you won't arrive at a good list of searched subqueries.
One simulation is not enough
And one simulation is not enough. When you ask the AI the same thing repeatedly, you will find that the AI always searches for slightly different queries and gives a slightly different answer. That "slightly" is sometimes more and sometimes less and can be precisely measured, but more on that some other time.
So if you base the query fan-out on one simulation, you will:
- Target queries that might have been only in that one simulation and will never be used for anyone else. In other words, a waste of time.
- You won't know the priorities of the searched subqueries. All subqueries look equally important in one simulation (except for their order). But as we will find out, some queries are more important than others.
How does QueryTool.ai solve this?
That is why we built QueryTool.ai.
QueryTool.ai prompts the AI multiple times, captures the used subqueries each time, and calculates the probability of them appearing in the query fan-out process based on their frequency.
The AI thus performs a query fan-out for the same prompt several times, but each time it searches for slightly different queries, downloads slightly different sources, and compiles a slightly different response. QueryTool.ai then analyzes these outputs.
QueryTool.ai has fine-tuned access via API so that the results resemble the real results we find in the given AI environment, e.g., Google AI Mode or ChatGPT. Gradeta SEO agency has been using it since June 2025 and as far as we know, no tool on the market does it this way to this day.
The output for the query CRM for small business looks like this:
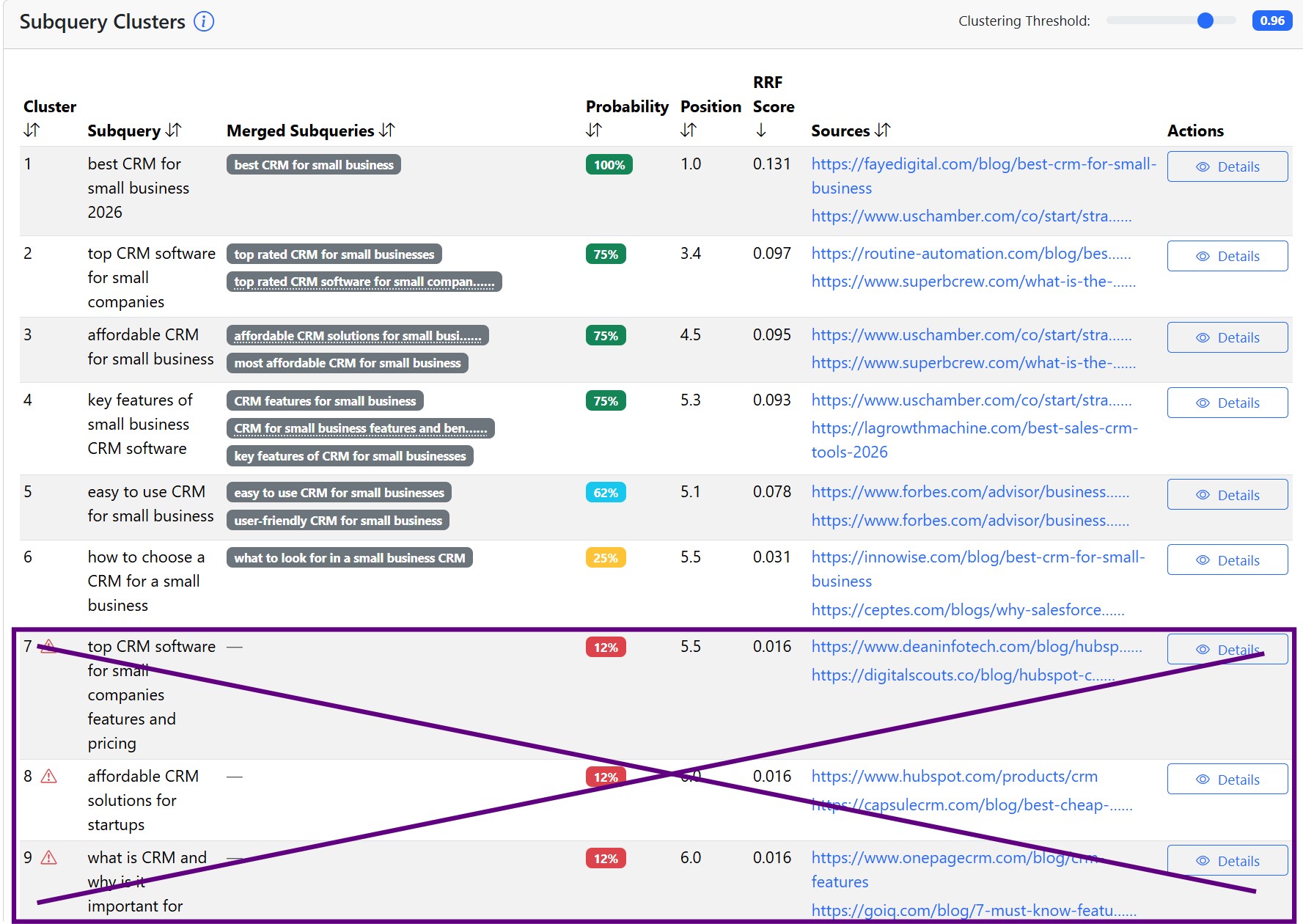
Crossed-out queries appeared in only one out of eight runs. So they are just random and we won't bother targeting them.
Probability is the new KPI
Even though the cost of creating good content has decreased significantly thanks to AI tools, it is still too expensive to chase random queries. I.e., we need to prioritize subqueries based on how likely it is that the AI will search for them.
As we already mentionned, we do this by asking the AI the same thing repeatedly. We let it do a query fan-out each time and then capture the actual searched queries. We call each attempt a run.
We cluster the captured subqueries across multiple runs by meaning. Sometimes subqueries differ only in upper and lower case letters, word order, or they are different words, but the meaning is the same. We evaluate in how many runs the given query, or its cluster, appeared. In the output, this is the Probability column.
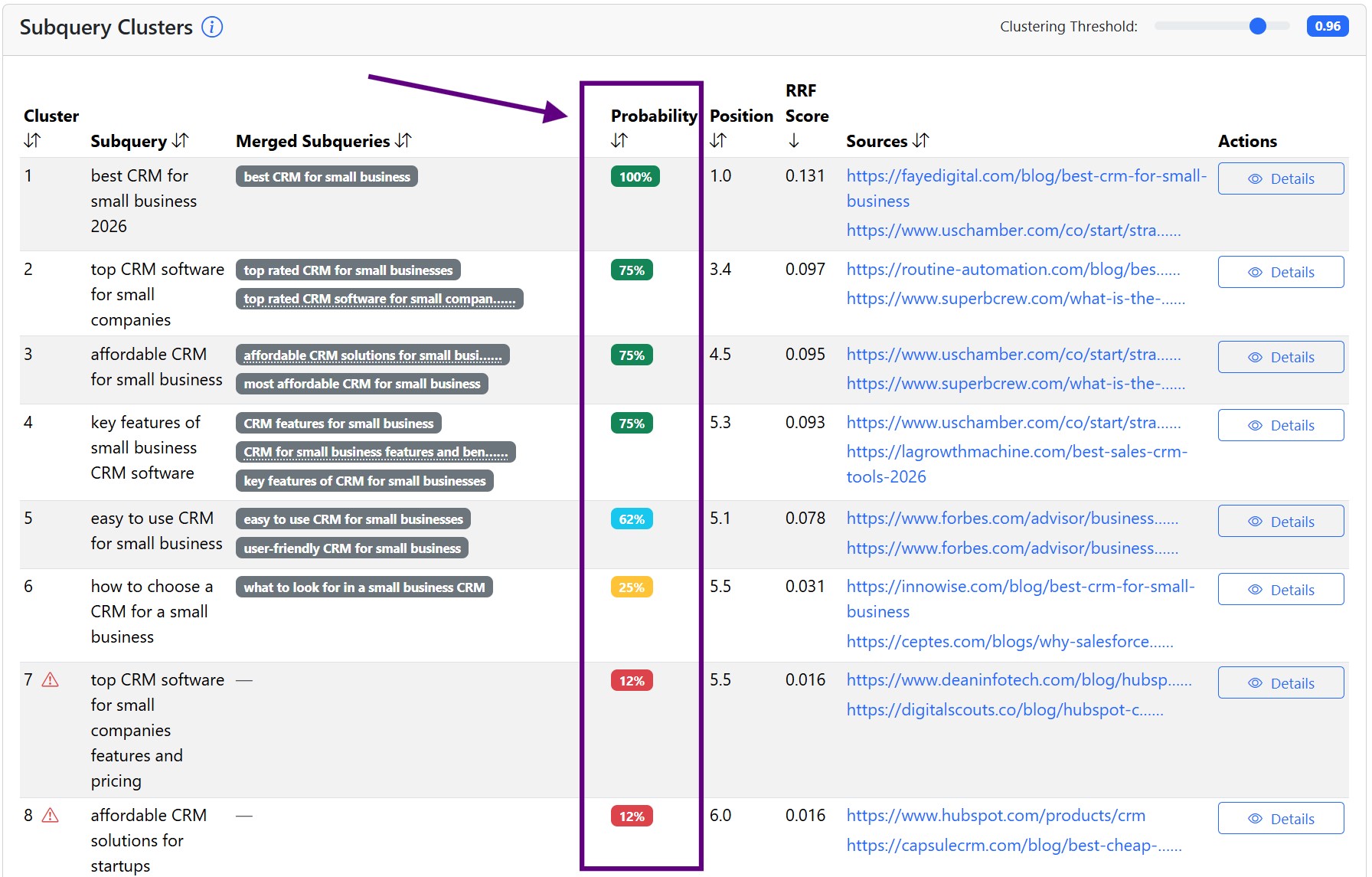
The second metric we track is the average position. In the case of subqueries, it is the average of what ranking the subquery had within the individual runs. If there are 2 subqueries that are searched in every run, meaning they have a 100% search probability, we want to know which one tends to be first. That one is more important, as it will probably influence the retrieved sources more. In the screenshot above, it's the Position metric.
And then we have a score that takes into account both probability and average position; we call it the RRF score, since it's inspired by the original RRF score (Reciprocal Rank Fusion Score). You can read about how it is calculated, but for now it's enough to know that the best prioritization of subqueries is by the RRF score, because it includes info about both probability and position.
If we dealt with search volumes for keywords, for subqueries we deal with their probabilities.
Sources within the query fan-out process
Beyond subqueries, we also want to know which sources are most likely to be used during grounding. These sources inform us about:
- What content performs well for specific subqueries. Querytool.ai maps sources to individual subqueries, so we know which sources for a given query are our competitors. It is similar to looking at the top-ranking results for a keyword in traditional Google Search. You see the subquery and next to it the sources that the AI selected for the given subquery.
- Third party pages that answer the subqueries. E.g., we won't cover the subquery "best SEO services" with our own article, but by finding out the sources that get into the AI and working to be mentioned there in a positive context. So-called citation building.
How we analyze sources
At the URL and domain level across all subqueries. One domain can have several URLs that get into the AI response as a source.
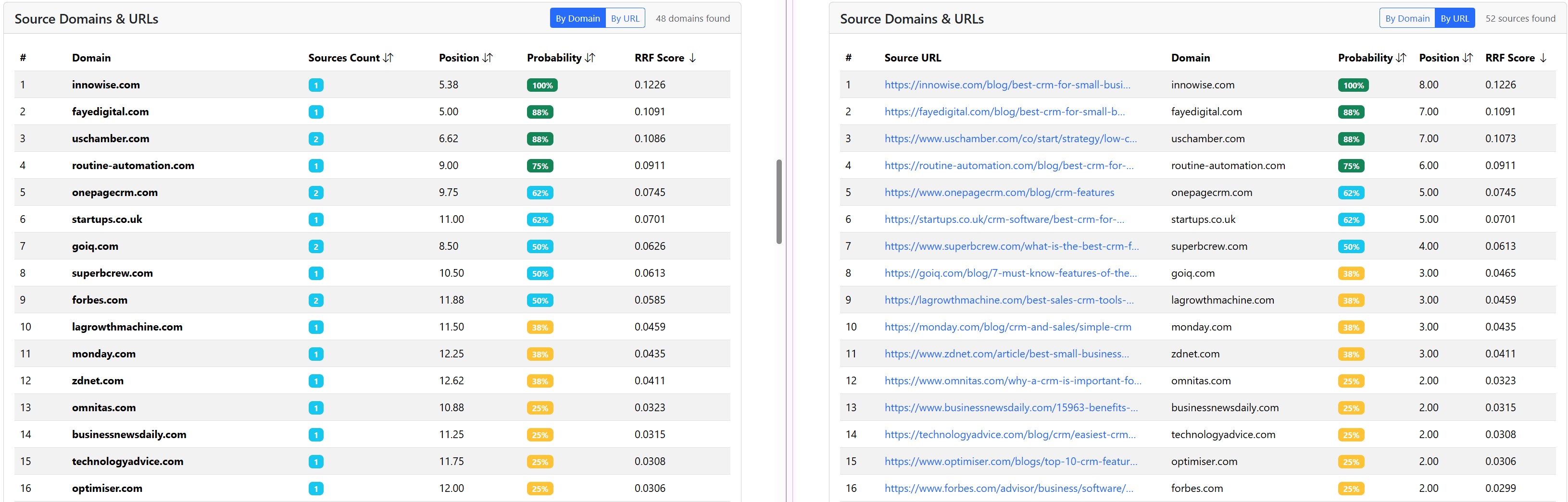
By source URLs mapped to subqueries.
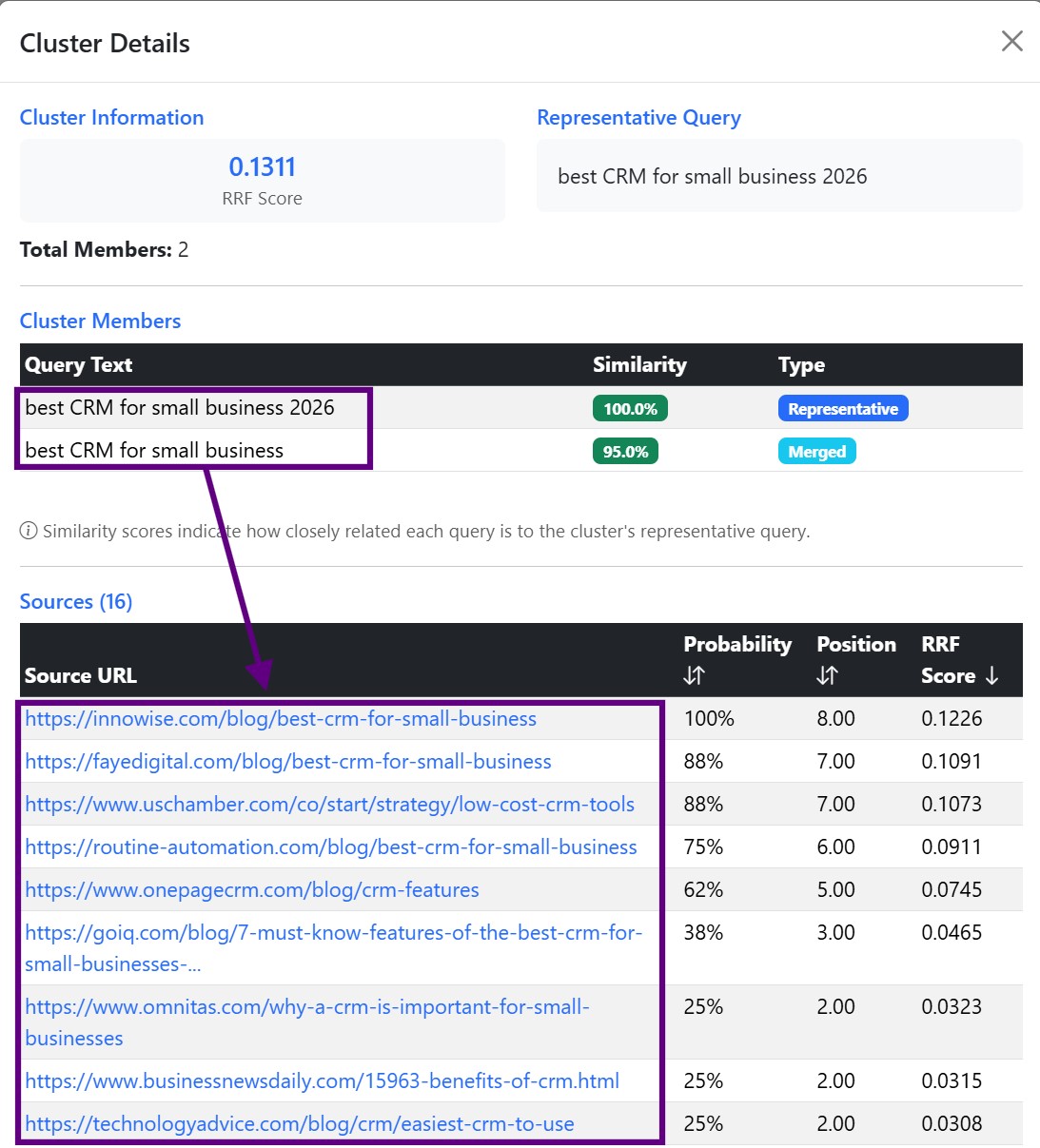
The metrics we address for sources are:
- Probability that the source will be used in the AI for the given main query.
- Average position when the source was used in the AI response.
- RRF score, which combines probability and position.
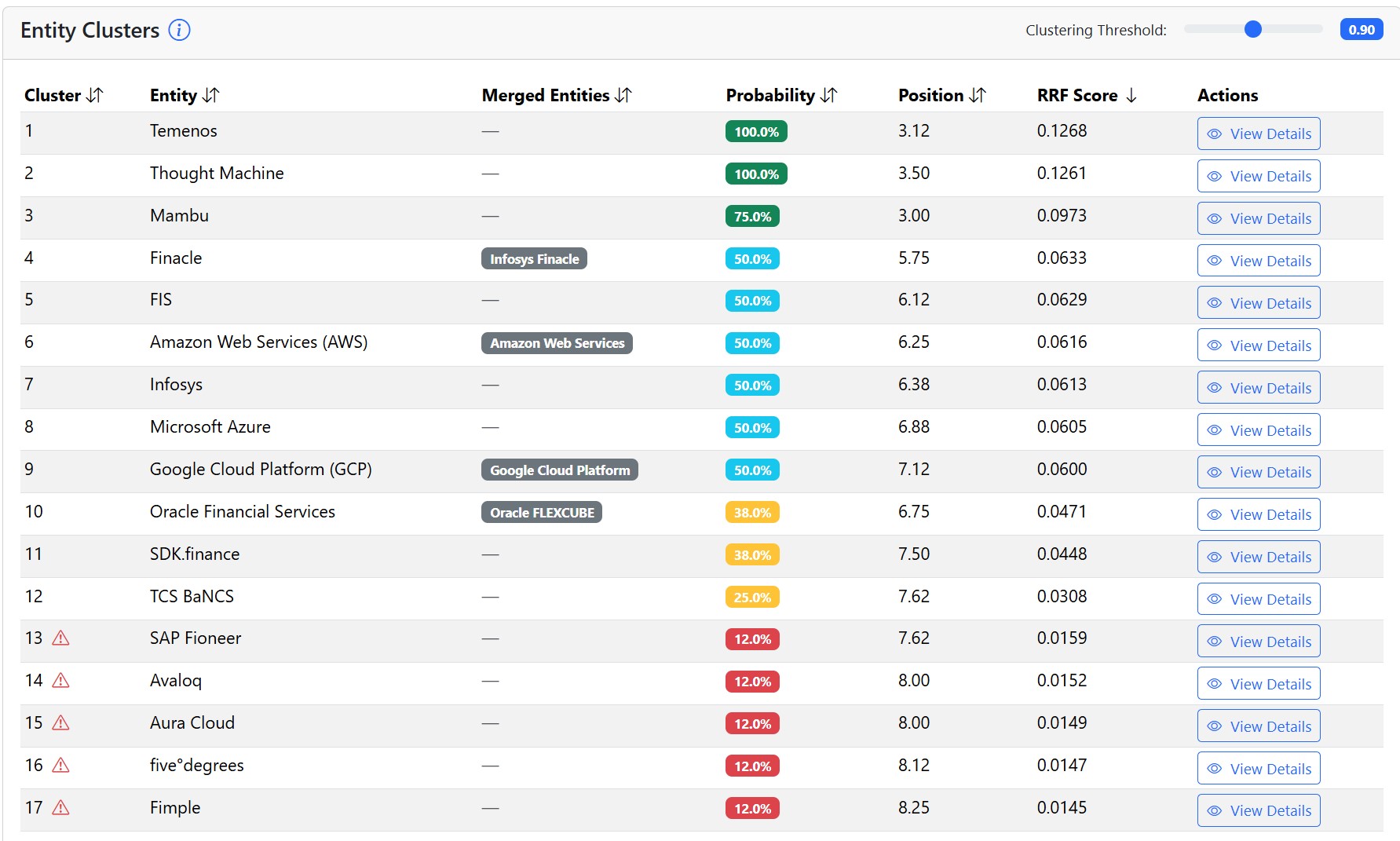
Entities within the query fan-out process
QueryTool.ai also tracks entities that were mentioned in the AI responses.
This is extremely useful for AI prompt tracking, although we have not connected it to a graph yet. It will be available within a month or two. For now, let's say that if your AI prompt tracker does not monitor responses across multiple runs and does not evaluate probabilities, then you are mostly tracking randomness.
For entities, we track the same metrics as for sources:
- Probability that the entity will appear in the AI response.
- Average position when the entity appeared in the AI response.
- RRF score, which combines probability and position.
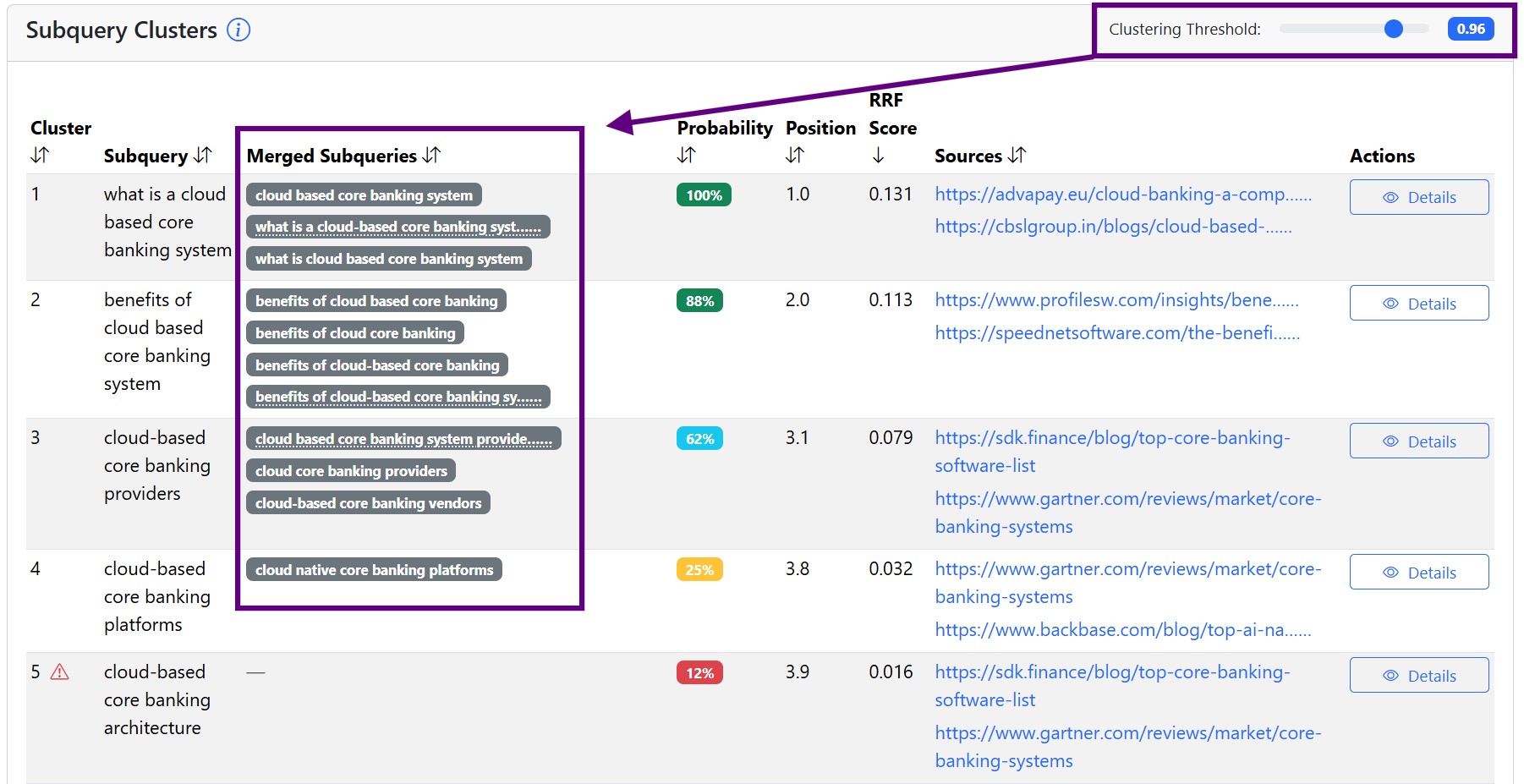
Why we need clustering for subqueries and entities
Since AI is probabilistic, even when it wants to search for the exact same thing, it will use slightly different words. E.g., when it searches for the queries "best SEO agency in New York" and "top SEO agencies in New York", it is searching for the same information, but with slightly different words. We don't want to deal with different terms just because of different wording. We want to cluster subqueries by the same meaning and find out how important the topic is, not specific words.
Similarly with entities, the AI will sometimes recommend Booking.com for accommodation and other times just call them Booking. We want to analyze entities, not every naming variation of the same entity.
QueryTool.ai has clustering set to some reasonable default values, which we can adjust as needed.
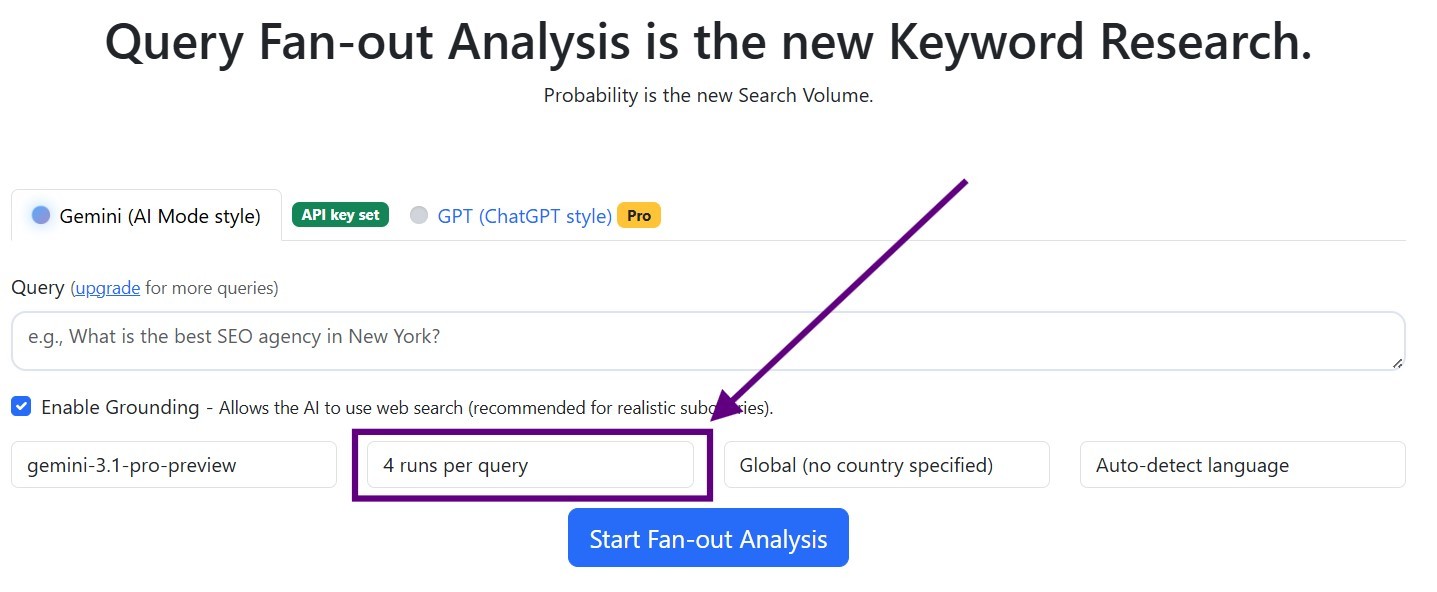
What is a good number of runs in QueryTool.ai?
The more runs you do in a query fan-out analysis, the more accurate results you get, but the more expensive it is. So we look for the lowest possible number of runs that will lead us to some reasonable insights:
- Around 80% of the subqueries that prove important after 50 runs already stand out after just 4 runs. I.e., they appear at least twice in 4 runs.
- We found that the sweet spot is 8 runs, where you catch over 90% of important subqueries.
- 20, 30, or 50 runs do not make sense considering what you uncover vs how much it costs. But feel free to try if you are interested and have the budget for it.
TOP entities
Determining TOP entities is a bit more complicated. Probabilities and positions are much harder to stabilize there. Our internal rule of thumb is that after 8 runs, the TOP 3 tends to stabilize. I.e., we consider movements outside the TOP 3 as random, and when we get into the TOP 3 at 8 runs, we take it as a result.
How much does a thorough query fan-out analysis cost?
The price of a query fan-out analysis consists of the price of the QueryTool.ai tool and the price for tokens via your API key.
1. QueryTool.ai is free for regular users
If you need to use the tool more, it starts at 29 euros per month.
2. The price of tokens through your own API keys
QueryTool.ai uses your API keys because this way it's cheaper. Gemini grounding is billed per Google's published pricing for your API key and project; there is no separate monthly grounding cap enforced by QueryTool.ai.
For one click on the "Start fan-out analysis" button, i.e., the default 8 runs for one query, you will pay Google or OpenAI from 4 to 10 cents. If you run at very high volume, provider-side limits and pricing apply as documented by Google and OpenAI. QueryTool.ai has the option to turn off grounding, but as explained above the resulting subqueries will be less reliable.
 Gradeta, as an SEO agency that uses it on a daily basis for dozens of clients, spends around 50 EUR per month for API through QueryTool.ai.
Gradeta, as an SEO agency that uses it on a daily basis for dozens of clients, spends around 50 EUR per month for API through QueryTool.ai.
But it's slow
Yes, running an 8-run query fan-out analysis can take close to a minute, and sometimes longer. The models respond at different speeds via the API and repeatedly.
But what you don't see is how much time it saves. Instead of reaching out to websites that were in the AI response as a source only by chance, you know exactly which sources are how important. And instead of creating content for random topics, you create content for queries that are very likely to enter the process of generating an AI response.
I'd rather wait a minute for a QueryTool.ai-style fan-out analysis than spend hours chasing randomness.
Basic differences in query fan-out processes between AI models
These are the most common AI interfaces and how they approach query fan-out.
Google AI Overviews
AI Overviews is powered by a custom version of Gemini model from Google; it usually shows up for traditional keywords (even for something like "seo"). AIO always uses query fan-out, that's how it is built. But generally, AIO searches for fewer subqueries than AI mode on Google, and AIO tends to stick to the language of the searcher or the searched query.
Google AI Mode
AI Mode is also powered by a custom Gemini model, but the prompts people use there look much more like chat-style questions. These are longer phrases and often direct questions. AI mode should always use query fan-out similarly to AIO.
In AI Mode, for the same question, you will get more query fan-out subqueries than with AIO, and AI Mode is less strict about sticking to the user's original language.
ChatGPT
ChatGPT is the well-known AI chat from OpenAI. People ask very detailed things in their chats, so the questions and prompts are much longer. ChatGPT generally searches in far fewer cases than AI mode or AIO and primarily tries to answer from memory. Basically, it searches only if it needs some fresh data. It will not use grounding for the query "what is seo".
If it does use grounding, its subqueries are much longer than with Google products. Probably because its search is worse than Google's and more detailed queries help finding the right results. Similarly to Google AI Mode or Gemini chat, it doesn't stick as much to the user's and query's language when searching for information.
Gemini chat
Gemini chat is like ChatGPT. It often answers directly from memory, but when it uses grounding, its subqueries are very similar to those from AI Mode.
These observations are based on recent months of simulations and experiments. Of course, everything changes so fast in AI that in some time it might be a bit or completely different.
How do you build a good list of key prompts?
Trying to guess exact prompts and and inventing highly detailed user wording in the style of "What are the top chef's knives, brand and model, for an amateur home chef with a budget <$300?" is, in my opinion, wrong approach. Very few people ask questions in that exact way, and we actually measure nothing because it's too specific.
Prompts should be as specific as possible regarding the product, but otherwise as broad as possible regarding the user's intent.
As broad as possible to the user's intent means that a simple "What are the top chef's knives?" is better than the example above. A simple "how to choose a mattress?" is better than "what mattress should I choose if I am a woman and have back problems".
As specific as possible regarding the product means that for an online mattress seller, "where to buy mattress online?" is a more relevant key prompt than "where to buy a mattress?". With the second question, the AI might also consider local stores, not just online stores.
Analyzed and tracked questions should primarily stem from keyword analysis. You will find plenty of questions in keywords, just phrased differently. Other sources include autosuggest prompts from AI interfaces such as Grok and Perplexity, Reddit, forums and discussions in general, social networks, online chat, internal surveys, and more.
Afterword
AI SEO is constantly evolving, but some systematic processes, tactics, and strategies that persist are already visible. Query fan-out is one of them.
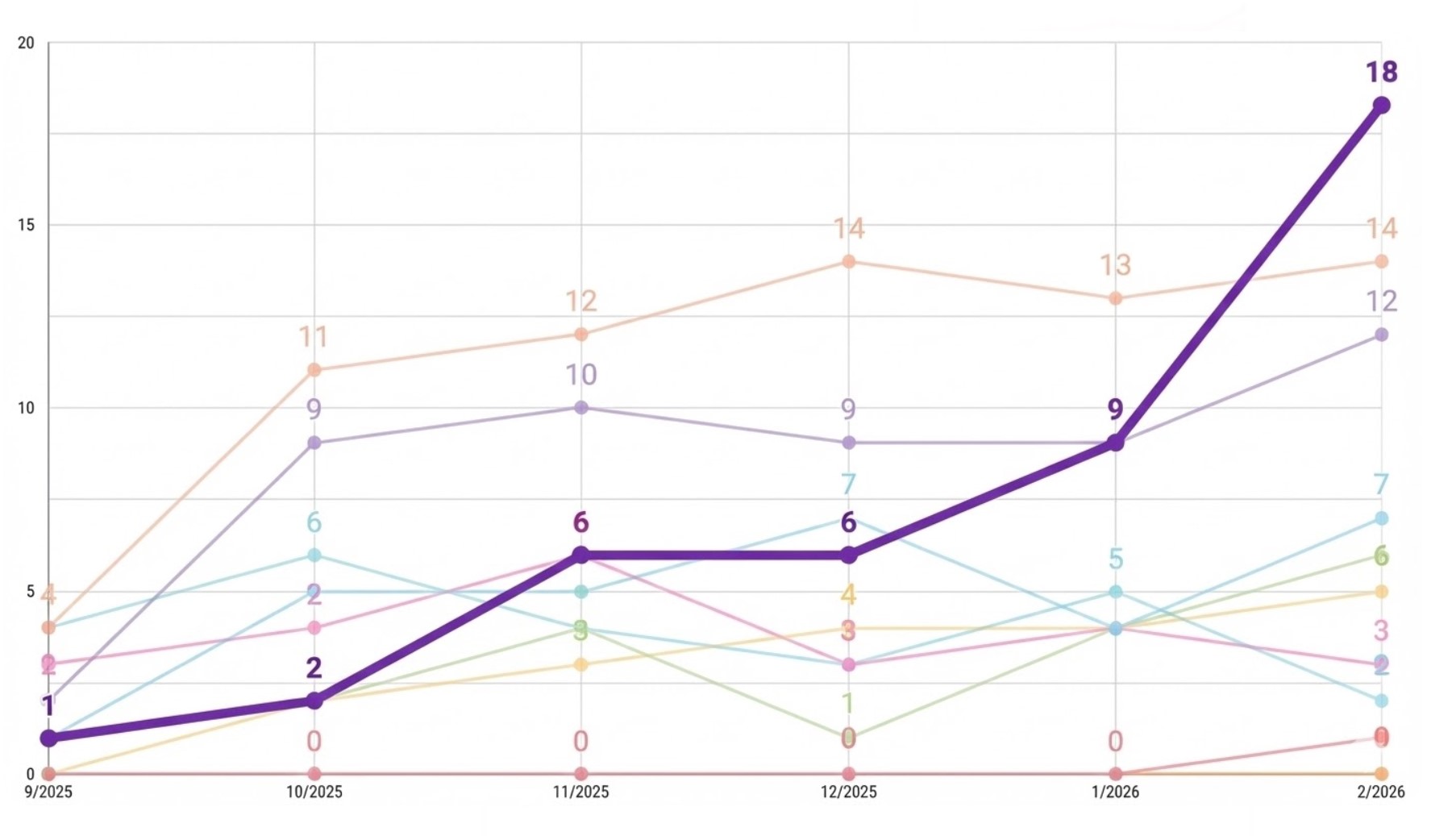
Gradeta been using query fan-out analysis for many months and have amazing results with it. You have probably seen case studies reporting traffic from ChatGPT up by thousands of percent. But those numbers are less impressive when the starting point was only a handful of visits.
We are more proud of things like this... A travel business where AI Overviews show up for commercial queries. So Gradeta tracks the occupied AI Overviews in Ahrefs and compare the client with its competitors. It started working on this in September and moved its client from second-to-last place to first within six months. In the process, they overtook websites with far more authority than the client's.
.